- JavaScript
다음과 같은 간단한 코딩 문제를 살펴보죠
Q. 최대 4차원 배열의 깊이를 가지는 변수 foo 안에 들어있는 모든 데이터를 1차원 배열로 출력하시오.
ex)
input: [[1], [[2,3]], [4,5,6], 7, [[[8,9,10,11,12],13],14]];
output: [1,2,3,4,5,6,7,8,9,10,11,12,13,14];case 1
최대 깊이가 4라고 했으니 4중 for문을 통해 간단히 작성이 가능합니다.
const result = [];
for (let a=0; a<foo.length; a++) {
if (typeof foo[a] === 'number') {
result.push(foo[a]);
} else {
for (let b=0; b<foo[a].length; b++) {
if (typeof foo[a][b] === 'number') {
result.push(foo[a][b]);
} else {
for (let c=0; c<foo[a][b].length; c++) {
if (typeof foo[a][b][c] === 'number') {
result.push(foo[a][b][c]);
} else {
for (let d=0; d<foo[a][b][c].length; d++) {
if (typeof foo[a][b][c][d] === 'number') {
result.push(foo[a][b][c][d]);
}
}
}
}
}
}
}
}
console.log(result); // [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 ]아주 간단하게 요구사항을 만족했지만 코드를 조금 리팩토링하고 싶어졌습니다.
Case 2
const result = [];
for (let a=0; a<foo.length; a++) {
if (typeof foo[a] === 'number') {
result.push(foo[a]);
continue;
}
for (let b=0; b<foo[a].length; b++) {
if (typeof foo[a][b] === 'number') {
result.push(foo[a][b]);
continue;
}
for (let c=0; c<foo[a][b].length; c++) {
if (typeof foo[a][b][c] === 'number') {
result.push(foo[a][b][c]);
continue;
}
for (let d=0; d<foo[a][b][c].length; d++) {
if (typeof foo[a][b][c][d] === 'number') {
result.push(foo[a][b][c][d]);
}
}
}
}
}
console.log(result); // [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 ]continue를 통해 for 문의 depth가 줄어들어 조금 더 보기 좋은 코드가 되었습니다.
여러분은 Case 1과 Case 2중 어떤 코드가 마음에 드시나요? 그 이유는 무엇인가요?
Case 3
foo.flat(5); // [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 ]Array 함수인 flat 을 이용할 수도 있습니다.
여러분은 Case 1, Case 2, Case 3 중에 어떤 코드가 마음에 드시나요? 그 이유는 무엇인가요?
Array 함수인 flat 은 Node 11에 포함되어 있습니다.
깊은 depth의 배열을 잘 안 쓰기 때문에 모를 수 있습니다.
flat을 몰랐다고 해도 이 글의 내용을 설명하는데 중요한 문제는 아닙니다.
아래를 더 살펴봅시다.
이 함수는 무슨 기능을 하는 함수일까요?
(함수 전체 중 일부를 발췌한 코드로 이 코드만으로 정상적으로 실행되는 코드는 아닙니다.)
function MyFavoriteFunction(predicate) {
// 1. Let O be ? ToObject(this value).
if (this == null) {
throw new TypeError('"this" is null or not defined');
}
var o = Object(this);
// 2. Let len be ? ToLength(? Get(O, "length")).
var len = o.length >>> 0;
// 3. If IsCallable(predicate) is false, throw a TypeError exception.
if (typeof predicate !== 'function') {
throw new TypeError('predicate must be a function');
}
// 4. If thisArg was supplied, let T be thisArg; else let T be undefined.
var thisArg = arguments[1];
// 5. Let k be 0.
var k = 0;
// 6. Repeat, while k < len
while (k < len) {
// a. Let Pk be ! ToString(k).
// b. Let kValue be ? Get(O, Pk).
// c. Let testResult be ToBoolean(? Call(predicate, T, « kValue, k, O »)).
// d. If testResult is true, return kValue.
var kValue = o[k];
if (predicate.call(thisArg, kValue, k, o)) {
return kValue;
}
// e. Increase k by 1.
k++;
}
// 7. Return undefined.
return undefined;
}if, while들의 depth가 깊지도 않고, 주석도 아주 잘 작성되어있습니다.
함수 이름도 멋지군요. MyFavoriteFunction !
이 함수는 어떤 기능을 하는 함수일까요?
39line 으로 작성된 이 코드는 여러분이 모두 아시는 Array.find 함수의 polyfill 입니다.
어떤 기능을 하는 함수인지는 몰랐지만, Array.find 라고하니 바로 이해가 되시나요?
처음부터 39줄의 코드가 아닌 Foo.find() 로 코드를 작성했다면 얼마나 좋을까요?
바꿔서 말하면, Array.find 라고 하면 모두가 바로 알아볼텐데, 39줄로 작성할 필요가 있을까요?
for-of, for-in 역시 같은 맥락
JavaScript의 함수는 일급객체 입니다.
/cc 일급객체란
1. 무명의 리터럴로 생성할 수 있다. (런타임 생성이 가능하다.)
2. 변수나 자료구조(배열의 요소나 객체의 속성값)에 할당 할 수 있다.
3. 다른 함수의 인자로 전달될 수 있다.
4. 다른 함수의 결과로서 리턴될 수 있다.함수의 추상화를 통해서 값 수준에서 함수를 추상화하여 단순히 값만 전달받아 처리할 수 있습니다.
즉, 함수가 간단해지고 읽기 쉬워지는 장점이 있습니다.
for (let i = 0; i < foo.length; i++) {
{...}
}
==>
foo.forEach((i) => {...});고차함수를 사용하면 추상화의 수준을 사고의 수준으로 끌어올릴 수 있습니다.
(for문의 구성을 모두 읽지 않고 즉시 코드를 읽을 수 있다)
추상화의 수준이 높아지는만큼 생산성이 높아집니다.
나는 일급객체는 뭔지 모르겠고 Airbnb를 찾아가보니…
많은 개발자분들께서 공부할 때나 회사 실무에서 javascript style guide 의 표준으로 airbnb의 style guild 를 채택하고 있습니다. 이는 이미 표준처럼 자리 잡고 있는 style guide 가 되어버렸죠.
그러다보니 개발자로 입문하거나 문법을 공부하거나 회사에서 style을 맞출 때 이 문서를 근간으로 하곤 합니다.
이 문서를 살펴보면 역시 for-of 대신 forEach를 사용할것을 권장하고 더 나아가 필요하다면 reduce사용을 권장하고 있습니다. (참고)
즉, 위에서 설명했던, 39줄의 코드보다 find가 익숙하기 때문에 find로 쓰는게 좋지 라고 생각했던 분이라면,
대부분의 개발자가 이 가이드를 통해 코드 품질을 유지하고있고 이 문서의 코드가 익숙한 개발자가 많기 때문에 우리도 그 스타일에 본인의 코드를 맞출 필요가 있습니다.
물론 100%! 무조건! airbnb 의 style guild 가 맞다! 라고 할 수 없겠지만요.
lodash를 왜 거부하는가?
lodash는 매우 좋은 라이브러리 입니다. 그리고 매우 많은 함수를 지원합니다. (lodash document)
하지만, 우리가 사용하는 lodash의 기능중에 find, map, assign 사용이 95%이상을 차지합니다. lodash가 제공하는 많은 함수 중에 아주 극 일부분만을 사용하고 있습니다.
마치 아메리카노 한 잔을 마시기위해 커피나무를 심는것과 같습니다.
node_modules를 통해 설치되는 lodash의 파일 용량입니다. 그리고 여러분이 작성하신 routes 파일의 용량과 비교해보죠.
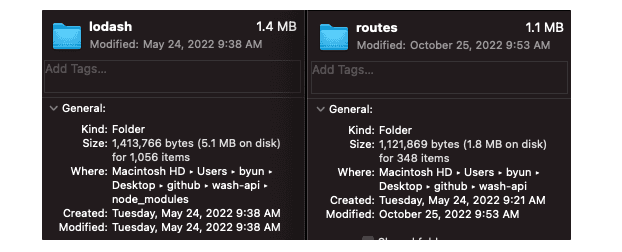
lodash의 프로젝트 크기는 여러분이 몇년동안 작성하신 코드보다 용량이 더 큽니다. 코드의 용량이 두배로 들어났다는 것은 것은 배포를 2배이상 느리가 만듭니다. 심지어 find, map, assign 모두 ES에서 기본으로 지원하는 함수임에도 이 함수들의 사용을 위해서 말이죠.
moment, dayjs 는 어떨까?
날짜 라이브러리로 moment 혹은 dayjs 를 많이 사용하고 있습니다.
여러분이 작성한 코드보다 dayjs는 과연 얼마나 더 좋을까요?
간단한 코드를 테스트해보죠.
new ***Date***('2022-11-01 15:00:00')
new ***Date***('2022-10-01 15:00:00')
2개의 date를 100만번 diff 계산해서 나온 벤치마크 결과입니다.
(실행하는 PC의 환경에 따라 속도는 달라질 수 있습니다)
for (let i = 0; i < 1_000_000; i++) {
diffDate(new Date('2022-11-01 15:00:00'), new Date('2022-10-01 15:00:00'));
}| 실행횟수 | dayjs | ES 문법 |
|---|---|---|
| 1 | 7.04s | 378.829ms |
| 2 | 6.984s | 372.289ms |
| 3 | 6.83s | 388.49ms |
| 4 | 6.916s | 376.063ms |
| 5 | 6.774s | 394.621ms |
| 6 | 7.006s | 377.683ms |
| 7 | 6.906s | 388.13ms |
| 8 | 6.958s | 390.238ms |
| 9 | 6.939s | 381.927ms |
| 10 | 6.756s | 383.171ms |
| avg | 6.91s | 383.14ms |
ES 내장함수는 평균이 383ms 인데 반면 dayjs 는 무려 6.9초가 걸렸습니다. 약 20배 가량 차이가 나고있어요.
이래도 오픈소스가 무조건 좋다고 생각할 수 있을까요?
오픈소스는 빠르게 개발할 수 있을지 몰라도 절대 당신이 작성한 코드보다 빠르고 좋다는 보장은 없습니다.
Left-pad 사건을 아시나요?
간단한 코드는 직접 작성하는 습관을 들이세요. (관련 블로그 링크)
프로젝트를 구성하는 아키텍처
Layered Architecture
역할과 책임을 분리하는 Layered Architecture 를 선호합니다.
그러기위해서는 api-codegen 을 살펴보도록 할게요.
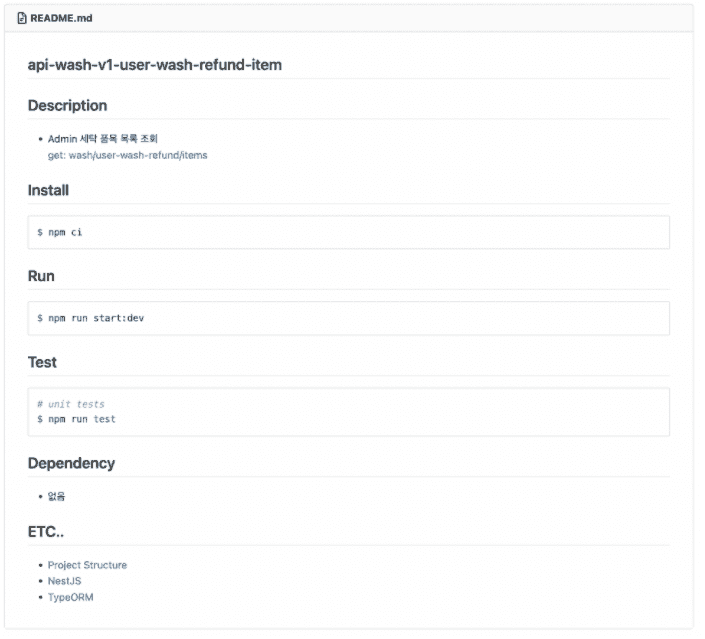
codegen 을 통해 자동으로 생성되는 프로젝트의 README.md 를 살펴보면 프로젝트에 포함된 함수 목록과 간단한 사용법 그리고 사용하는 주요 모듈에 대한 document 링크가 포함되어 있습니다.
그 중 중요한 Project Structure 링크를 살펴보도록 합니다.
 (utils 아래는 생략)
(utils 아래는 생략)
이 프로젝트의 구조는 nestjs 의 구조를 기본으로 따라가고 있습니다. (물론 100% 같지는 않습니다)
nestjs는 전형적인 controller, service, dao 레벨로 구분되어지는 Layered Architecture 를 가지고 있습니다.
프로젝트를 구성할 땐 역할과 책임에 대해 나누어야..
controller
컨트롤러의 역할은 프론트에서 보내주는 데이터를 잘 받아오는 역할을 합니다.
예를들어 코드를 살펴보면
const { foo, bar } = req.params;
if (!boo) new Throw BadRequestException();
if (!bar) new Throw BadRequestException();
return serviceFunc(foo, bar);예제와 같이 프론트가 넘겨준 데이터를 검증하는 일 외에는 어떠한 일도 해서는 안됩니다.
그럴 가능성은 거의 없겠지만, chrome 의 spec이 headers라는 이름에서 heads 라고 바뀐다고 하면 이 부분을 파싱하는 Controller 에만 영향이 가야합니다.
이 영향이 service, dao 까지 넘어가면 안됩니다.
service
프로젝트이 핵심 비즈니스 로직이 들어가는 공간입니다.
정책에 관련된 내용과, controller에서 넘어온 데이터를 dao에 데이터를 조합하여 다시 돌려주는 역할을 할 공간입니다.
dao
데이터에 접근하는 공간입니다. 데이터의 저장소는 가장 많이 사용되는것중에 하나는 db가 있겠죠.
저의 경우엔 여기서 TypeORM 을 사용해 RDB에 접근하고있습니다.
이 Layer도 마찬가지로, 어느날 MySQL을 사용하다가 MongoDB를 사용하겠다고 했을 때, 이에 대한 dependency는 DAO에만 존재해야 합니다. MySQL을 사용하던, MongoDB를 사용하던 Controller와 Service입장에서는 관여할 필요가 없습니다.
TypeORM을 선택한 이유
선택지가 있었던 후보군은 다음과 같습니다.
- raw query
- sequelize
- typeorm
- knex (querybuilder)
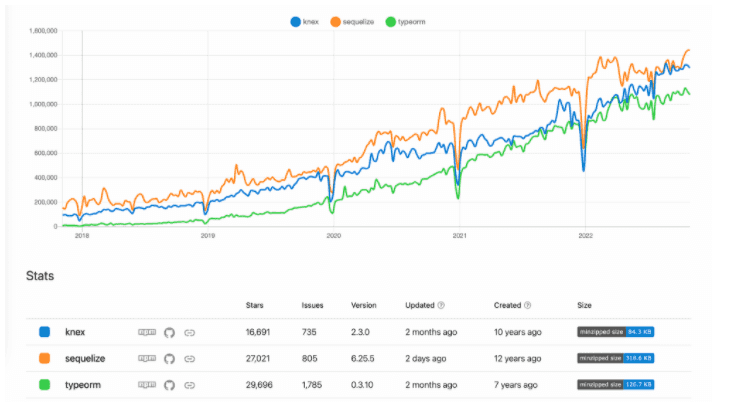
어떤 NPM 모듈을 사용할 것 인지를 고민할 때에 중요하게 확인해야하는 요소들이 있습니다.
- 얼마나 자주 업데이트가 되는지
- 얼마나 issue를 빠르게 처리하고 있는지
- 얼마나 많은 사용자들이 사용하고 있는지
그것을 비교해봤을 때, 2022년 11월 10일 기준으로 Sequelize와 TypeORM, Knex은 뭐가 더 낫다고 판단하기 어려울만큼 둘 다 사용자가 많고, 최근업데이트, 이슈도 잘 처리해주고 있습니다.
raw query는 고민도 없이 탈락
-
raw query는 코드 작성을 편하게 합니다. (query → builder or orm 문법에 맞춰 작성하지 않아도 됩니다)
-
다만, raw query는 params의 검증에 더 많은 코드가 필요합니다.
ex)const updateFunc = (foo, bar) => { let q = ''; if (foo) { if (!q.length) { foo += ','; } foo += 'set foo = ' + foo; } if (bar) { if (!q.length) { bar+= ','; } bar += 'set bar = ' + bar; } } -
query 오류에 대해 빌드레벨에서 잡아낼 수 없습니다.
ex)const query = 'select * from foo wh t = 1'; // 런타임에서 query error 발생
Sequelize
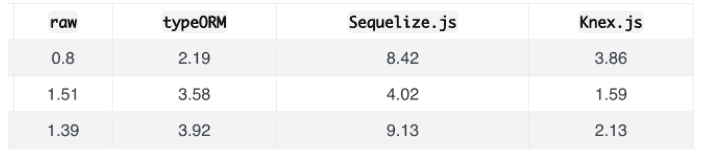
sequelize도 좋은 방안 중 하나였습니다.
다만, 벤치마크 결과에서 다른 모듈에 비해 큰 속도차이가 보였습니다.
TypeORM
TypeORM은 적당한 속도와 많은 사용자, isuue처리도 잘 되고 있었습니다. 그래서 최종적으로 나온 후보는 Query Builder인 knex와 TypeORM 이었죠.
둘 다 어떤걸 선택해도 문제는 없다고 생각했어요.
둘 중 TypeORM을 선택했던 이유는 구성원들의 미래 경력 때문이었습니다.
요즘은 한 회사에서 평생 재직하는분을 찾아보기 힘들정도가 되었죠. 직원은 또 언젠가는 여기에서 다른 회사로 이직을 할 것이고, 그 때 지금 다니는 회사가 화려하고 멋진 이력은 못만들어주더라도 피해를 줘서는 안된다고 생각해요. 어쩌면 그게 더 윗선인 리더급에 있는분들이 해야할 의무중에 하나라고 생각해요.
회사의 성장도 중요하지만 개인의 성장도 무시해서는 안되는 것이죠.
그래서 함께 일하는 동료들의 미래를 위해서는 Query Builder 보다는 당장은 러닝커브가 있겠지만 ORM을 써보는게 좋다고 생각했어요. (물론 저도 ORM을 많이 써봐서 잘하거나 그런 상태는 아니었어요)
그렇게 TypeORM을 선택하게 되었습니다.
정리
제가 코드를 작성하고, 프로젝트 구조를 구성할 때 신경쓰고 중요하다고 생각하는점들에 대해 정리해봤어요.
코드 퀄리티, 코드 품질에 대한 얘기를 많이 합니다. 관련 서적도 많이 나와있구요. 과연 코드의 퀄리티, 품질이란건 어떤걸 의미하는걸까요?
단순히 line만으로 1000줄짜리 코드보단 500줄짜리 코드가 퀄리티가 높다고 말할 수 있을까요?
제가 생각하는 코드 퀄리티란, 그 코드를 처음보는 누군가가 봐도 쉽고 빠르게 읽혀지는 코드라고 생각합니다. 한 곳의 수정에 대한 영향이 더 많은곳으로 뻗어나가지 않게 구조를 잡는거라고 생각합니다.
각종 개발 서적에서 설명하는 함수명, 변수명, 폴더분리 에서 부터 시작해서, TDD, DDD, MSA 등 이름은 다르지만 다 같은 맥락이지 않을까 생각해요.