근황
요즘 심심치 않게 많은 회사들이 모놀리식에서 MSA로 전환한다는 것을 들을 수 있다. 대형 IT 기업들부터 이제 막 시작하는 스타트업조차도 처음부터 MSA 구조를 채택하기도 한다.
이 글을 작성하게 된 주요 원인은 과연 MSA는 장점만 존재할까? 왜 다들 MSA로 전환하는 걸까에서 시작되었다.
그리고 나 또한 최근 1년간 회사에서 MSA를 전환하는 과정을 겪었다. 그리고 곧 오픈을 앞두고 있다.
MSA 개발
많은 회사들처럼 지금 재직 중인 회사에서도 모놀리식 서버 구조에서 MSA 구조로 개편하고 있고 곧 오픈을 앞두고 있다.
기존 레거시 시스템은 하나의 서버에 모든 API가 담겨있는 전형적인 모놀리식 구조이고 6~7년을 운영되었는데, 너무 많은 개발자를 거쳐가다 보니 여러 문제점들이 발견되고 있다.
- 수많은 개발자를 거치면서 코드가 너무 거칠다.
부끄럽게도 회사에 코드 리뷰 문화가 존재하지 않는다. 따라서 각자 개성이 강한 코드들이 여기저기 묻어있다 보니 유지 보수하면서 어려움에 부딪히곤 한다.
함수를 여러 군데서 사용하고 있고 api를 어디서 호출하는지조차 알 수 없다 보니 새로운 기능을 추가하고자 할 때 파악해야 하는 내용이 너무 많다. - Mongo DB 를 메인으로 사용하고있는데, 특정 컬렉션에 대해 부하가 너무 심하다. 컬렉션 하나에 모두 때려 넣었다. 아마 초기에 빠른 개발을 위해 이렇게 개발했을 거라 생각한다.
- 너무 많은 I/O로 인해 대부분의 API 가 제속도를 내지 못하고 있다. 2번과 연결되는 내용이긴 한데, 쉽게 말해 특정 컬렉션 하나의 row에 모든 정보가 들어있다고 생각해도 과언이 아니다. 회원정보부터 결제정보, 구매정보 등등!
- 추가/수정된 기능에 대해 전혀 다른곳에서 사이드이펙트가 발생한다.
개발되어 배포된 API에 대해 어디서 어떻게 사용하고 있는지 문서화가 전혀 되어있지 않다. 심지어
response데이터 중에는 프론트에서 쓰지도 않지만 리턴해주는 데이터들이 아주 많다. (원인으로는 3번과 연결된다.)
더 많은 이유들이 있겠지만, 위 내용들에 의해 시스템 구조를 한번 갈아엎으면서 MSA로 개선하기로 결정되었다.
기술 스택의 변화
새로운 MSA 에 사용할 기술스택은 다음과 같다.
- TypeScript + NestJS
- AuroraDB (AWS)
- Kafka
- Redis
가장 큰 변화로는 MongoDB 를 완전 걷어내고, 다른 도메인과의 통신 혹은 내부 도메인끼리 통신을 위해 Kafka를 도입하였다.
아키텍쳐
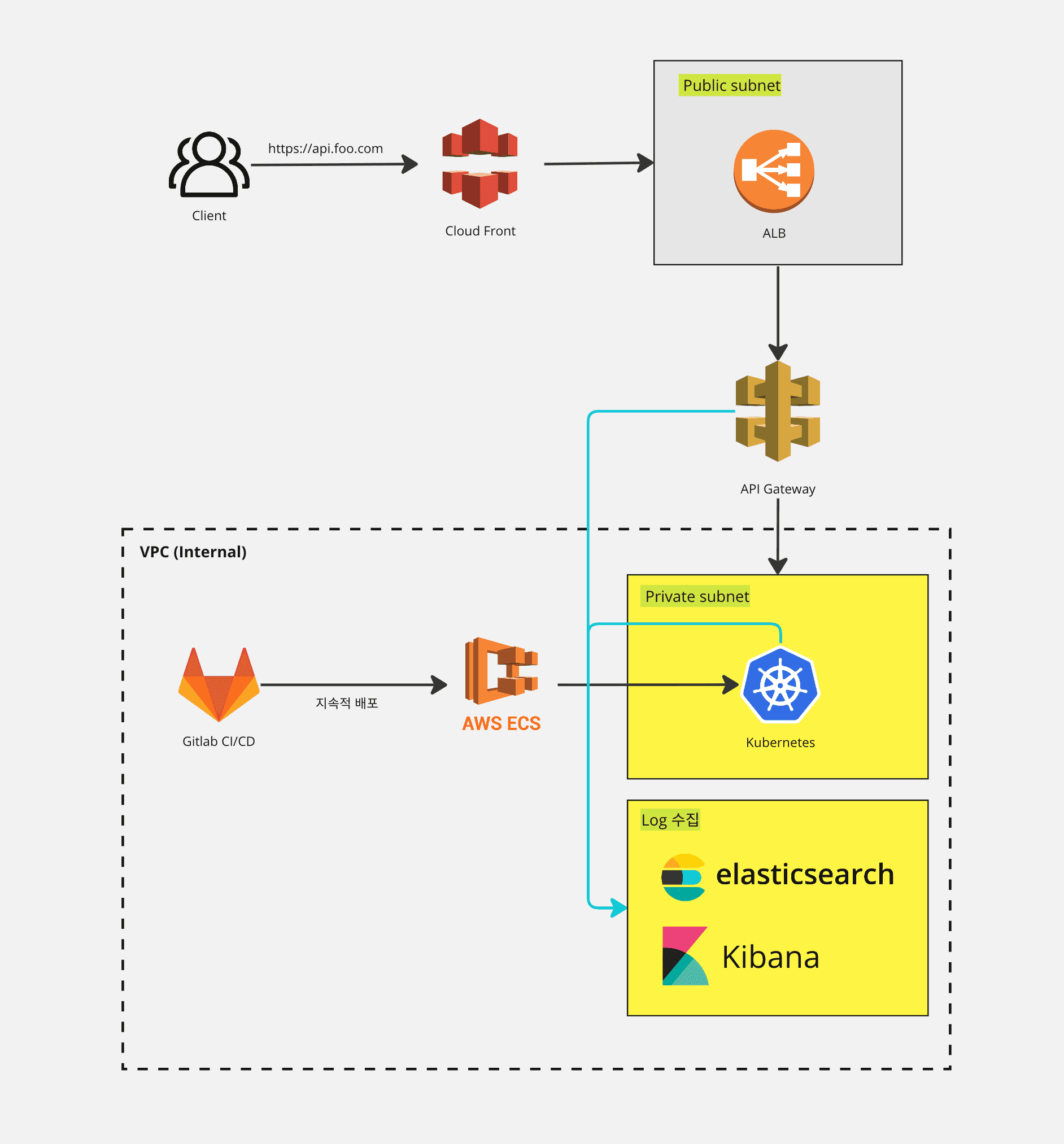
인프라 영역은 자세히 알지 못하기에 중간중간 빠진것들도 많다. (더 공부해야할 부분이기도 하다) 사내 DevOps 분의 도움을 받아 대략적인 그림을 그려보았다.
조금의 설명을 보태자면, 사용자는 Cloud Front 에서 제공되고있는 정적 파일 통해 프론트에 접근하게되고, api의 호출이 이루어진다. alb, api gateway 를 통해 다음 목적지를 정한 후 internal 영역에서 eks로 서비스되고있는 api 서버로 접근한다.
좀 더 특이한 아키텍쳐
일반적으로 MSA 서버라고 한다면, Domain단위로 서버를 띄우기 마련이다. 예를들어 회원서버, 결제서버, 알림서버 등등이다.
하지만, 특이하게도 우리 회사가 채택하고있는 서버의 단위는 endpoint이다.
즉, https://api.foo.com/users 와 https://api.foo.com/users/:userId 는 다른 서버이다.
다른 서버이기때문에 gitalb의 repository도 분리하여 개발하고 따로 배포한다. 이런 초마이크로(?) 서버의 경우에 개발하다보니 장단점이 명확히 보이게 되었다.
장점
- 트래픽이 몰리는 특정
endpoint에 대해서만Scale-out을 할 수 있다.
Scale-out관점에서 보면 어쩌면 매우 효율적이다 - 새로 추가하거나 기존 코드를 수정할 때 영향받는 사이드이펙트가 매우 적다.
그러다보니 새로운 개발자가 왔을 때 해당endpoint에 대해 새로운 언어로 작성하더라도 빠르게 배포가 가능하다.
실제로 이 장점덕분에 새로운 요청에 대해 매우 빠르게 개발해줄 수 있다. - 배포 단위가 매우 작아진다.
단점
- 시스템 복잡도가 매우매우 높아진다.
어쩌면 매우 높은 러닝커브가 될 수 있다. - 코드의 재사용성이 매우 떨어진다.
비슷한 기능을 하는 api 들이 있을텐데, 서버가 분리되어있다보니 비즈니스 로직을 재사용할 수 없다. - 서버 비용이 매우 많이 든다.
AWS에서 가장 작은 단위의 EC2를 사용하더라도 서버가 하는일에 비해서는 낭비가 발생한다. - 관리해야하는 서버가 매우 많다.
주의해야할 점
모노리식 아키텍쳐에 비해 MSA 는 특히 더 많은 고려해야할 점들이 있다.
우선 서버간 통신이 매우 많아진다. 특히 여기서 채택중인 아키텍쳐의 경우 도메인 내에서도 통신해야할일이 많았다.
그러다보니 일단 MSA를 하기위해서는 정해야하는 규칙들이 매우 많다. 폴더명부터 시작해서 key (redis등에서) 규칙들, kafka topic을 정하는 규칙들 등등
또 MSA 에서 어쩌면 제일 중요하다고 생각되는 부분은 서버간 트랜잭션 처리였다. MSA에서 트랙잭션을 처리하는 방법에 대해서는 구글에 검색해보면 몇가지가 나오긴 한다.
처음엔 SAGA 패턴을 사용하려고 계획했었는데, 어찌어찌하다보니 나중에는 2PC 방식으로 개발되었다.
다른 도메인을 호출하는 모든 통신마다 트랜잭션 처리를 하고있는건 아니지만, 결제쪽은 중요하다고 판단하여 2PC 방식으로 트랜잭션 처리를 해두었다.
지금 다시 개발한다면
만약 이 경험을 기반으로 1년전으로 돌아가 다시 MSA를 설계한다면 어떨까?
우선은 endpoint마다 서버를 띄우는 방식에 대해서는 더 많은 고민이 필요하다.
아무래도 코드 재사용이 어렵다보니 생산성이 떨어졌다. 그리고 관리하는 서버가 많아지다보면 ~~api에 ㅇㅇ한 문제가 있어요 라는 요청을 받았을 때 해당 api가 어느 project에 있는지 바로 찾지 못하는 경우도 발생했다. (이를 방지하기위해 repository이름을 정하는 규칙은 정해져있다. 하지만 지키지 않은 몇몇..)
또 과연 MSA가 우리에게 맞을까? 라는 고민부터 다시 해보게 될 것이다. 회사 규모를 보거나 (매출도 중요하지만 개발팀 규모도 중요하다) 트래픽을 봤을 때 오버엔지니어링이지 않을까 라는 고민도 많이 했다. (특히 과하게 발생하고있는 서버비용)
결론
구글에서 MSA 관련 글을 찾아보면 처음부터 너무 크게 개발하지 말라는 글도 있다. 우리 회사가 이에 해당했다.
나도 1년간 개발하며 드는 생각으로는, 처음에는 외부 서버들을 하나씩 하나씩 분리해가는게 좋겠다고 생각이 든다. (로그서버, 알림서버 등등)
그리고 만약 꼭 MSA로 한번에 넘어간다고 하더라도 도메인별로 서버를 띄운 후 트래픽이 몰리는 endpoint에 대해 서버를 분리해가는게 좋지 않을까 생각이 든다.
마지막으로 최종 결론은 MSA.. 지금보다 더 많은 고민을 해보고 시작하라 이다.