안녕하세요.
저는 온라인 강의 서비스를 제공하는 회사에 재직하며 백엔드개발을 담당하고 있습니다.
동영상 재생기록에 대한 저장 기능을 구현하면서 겪은 삽질기를 공유하고자 합니다.
여러가지 요구사항들이 있었지만 요약하면 두가지가 핵심이었습니다.
- 사용자들의 일별, 시간별 시청기록
- 동영상 이어보기
초기 개발 과정
위 요구사항을 만족하기 위해 기능개발을 시작했습니다.
간단한 아키텍쳐를 그려보겠습니다.
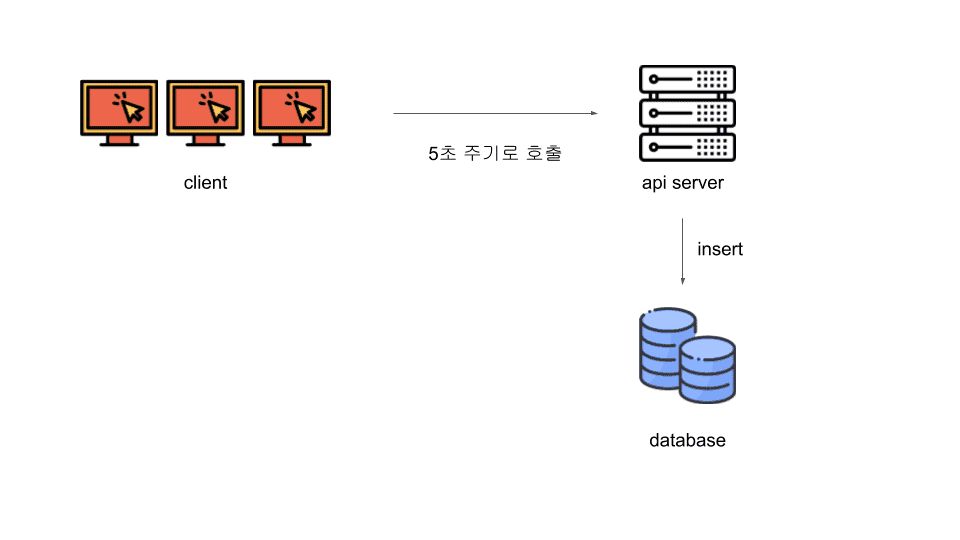
위와같이 아주 간단하고도 빠르게 구현가능한 아키텍쳐를 가지고 기능개발을 했습니다.
사용자들의 시청지점은 table에 5초단위로 저장되고 있으며, 시청 통계는 이 5초단위로 저장한 데이터를 배치작업을 통해 새벽에 하루치 데이터를 생성해내고 있습니다.
Database에 무리가 좀 가겠지만 우리의 Database 성능은 충분했습니다.
그렇게 한달을 운영하고 어느날 Database 용량을 확인했습니다.
처음 생각과는 달리 동시접속자수가 적게는 100명에서 많게는 300명까지 들어오다보니 table에 초당 100건정도의 데이터가 쌓이고 있었습니다.
1초에 100건
1분에 6,000건
1시간에 36,000건
1일에 864,000건
대략적인 계산은 이렇지만 데이터를 보면 하루에 적게는 80만건 ~ 많게는 120만건 정도 쌓였습니다.
table의 row수는 약 1억건이 넘어섰고, 용량은 4.7Gb가 되었습니다.
1억건이 쌓였습니다. 다른 테이블들은 데이터가 많아야 10만건이었는데 말이죠..
내가 개발한 시스템에서 생성된 데이터가 다른 시스템을 괴롭히는 지경에까지..
데이터 병합
5초마다 쌓이는 사용자 데이터를 살펴보면 데이터들이 연결된다는 점이 있습니다. 예를들어,
| id (PK) | 시간 | 사용자 ID | 동영상 ID | 시작시점 | 끝지점 | 시청시간 |
|---|---|---|---|---|---|---|
| 1 | 2020-01-15 09:09:31 | 1 | 7 | 10 | 15 | 5 |
| 2 | 2020-01-15 09:09:35 | 1 | 7 | 15 | 20 | 5 |
| 3 | 2020-01-15 09:09:41 | 1 | 7 | 25 | 30 | 5 |
| 4 | 2020-01-15 09:09:46 | 1 | 7 | 30 | 35 | 5 |
| 5 | 2020-01-15 09:09:51 | 1 | 7 | 35 | 409 | 5 |
위 5개의 row는
| id (PK) | 시간 | 사용자 ID | 동영상 ID | 시작시점 | 끝지점 | 시청시간 |
|---|---|---|---|---|---|---|
| 1 | 2020-01-15 09:09:31 | 1 | 7 | 10 | 35 | 25 |
한개의 row로 합칠 수 있음을 확인했습니다.
그래서 기간을 정하여 약 9.5천만건에 대해 데이터 병합을 시도했습니다.
table에는 실시간으로 계속 새로운 데이터가 쌓이고 있으므로 더욱 주의해야했습니다.
프로그램은 하루치 데이터를 가져와 병합하고 새로운 테이블에 저장해주는 간단한 코드였습니다.
데이터 병합을 위한 프로세스는 다음과 같았습니다.
1. 테이블(xxxx_log)에 저장되어있는 약 9.5천만건의 데이터를 병합하여
새로운 테이블(xxxx_log_deflagment)에 저장한다.
2. 3달치의 데이터를 삭제한다.
3. 새로운 테이블(xxxx_log_deflagment)에 저장되어있는 병합된 데이터를
기존 테이블(xxxx_log)에 insert한다.며칠동안 병합하는 프로그램코드를 작성하였고, 테스트가 완료되었을 때 그날은 프로그램작동을 켜두고 퇴근했습니다.
약 9.5천만건의 데이터를 병합하여 새로운 테이블에 저장한다.
15:00 쯤 시작된 프로그램 가동은 다음날 13:00 쯤 끝났습니다. 약 22시간이 소요되었습니다.
중간중간 멈춰서 한두번 프로그램을 재시작 해주기는 하였으나 큰 문제없이 정상적으로 종료되었습니다.
row수는 95,686,125건이었던 데이터는 병합 후 22,912,499 로 약 1/4로 줄었고,
용량은 4.7Gb => 990Mb로 약 1/5로 줄었습니다. 🙌
3달치의 데이터를 삭제한다.
3달치 약 9.5천만건의 데이터를 삭제해야 합니다. 실시간으로 데이터가 들어오고 있는 상황에서 오래걸리는 쿼리를 어떻게 해결할 수 있을까?
우리는 다른 방법을 생각해보았습니다.
병합대상인 3개월치 데이터를 제외하면 약 500만건의 데이터가 있습니다.
9.5천만건을 처리하는것 보다는 500만건 처리하는게 빠르지 않을까?
그래서 다음과 같이 해보려고 합니다.
1. xxxx_log테이블의 3개월치를 제외한 약 500만건의 데이터를 xxxx_log_deflagment에 복사한다.
2. xxxx_log테이블의 이름을 xxxx_log_temp로 수정한다.
3. xxxx_log_deflagment의 이름을 xxxx_log로 수정한다.실제로 500만건 데이터의 복사는 금방 실행되었고, 테이블명 수정 또한 00ms 대로 종료되었습니다.
약 9,500만건의 데이터를 조작하기보다는 약 500만건 데이터의 조작으로 더욱 편한 작업이 되었습니다.
xxxx_log_temp는 데이터 병합이 문제가 될 경우를 대비해 새로운 데이터베이스를 만들고 그곳으로 옮겨두기로 하였습니다. (백업 목적)
알게된 점
- MySQL는 데이터의 용량이 많더라도 테이블명 수정하는 시간에 영향을 받지 않는다.
- MySQL에서는 데이터베이스간에도 테이블 이동이 가능하다.
alter table database_name.table_name
3. MySQL에서는 테이블이 링크형태로 데이터베이스에 저장되어있는 듯 하다.
약 1억건의 테이블의 데이터베이스를 옮기는데, 시간이 오래걸리지 않는다.
4. row 데이터는 연속되는 데이터들인데, 5초마다 row를 생성하는것은 비효율적이다.
5. 생각보다 사용자가 많아서 table이 오래 버티지 못할것이다.
이대로는 오래 버티지 못한다!
회사의 규모는 커져가고 있었고, 동시접속자는 계속 증가하고 있었습니다.
그만큼 초당 쌓이는 데이터의 숫자도 늘어나고 있습니다.
오래 버티지 못하고 또 병합해야 하는걸까.
우리는 새로운 아키텍쳐를 설계했습니다.
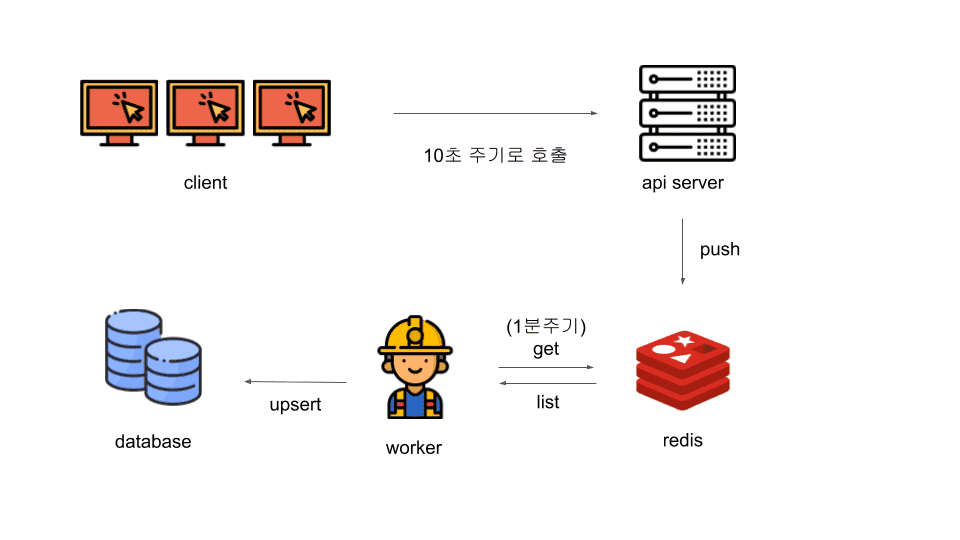
바뀐점
- Client는 5초주기가 아닌 10초주기로 호출
- Server는 Database에 직접 저장하지 않고, Redis에 저장
- Worker의 Cron Jobs이 1분마다 실행하면서 Redis의 데이터를 가져와서 병합처리 한 후 Database에 저장
- 저장할 때에는 동일한 동영상 ID가 있다면 update 없다면 insert
개선된 점
- 이전에는 raw 데이터 (xxxx_log)데이터를 하루가 지나야 배치를 통해 통계데이터를 생성했습니다. 따라서 사용자들은 오늘 시청한 동영상시간을 다음날에야 확인할 수 있었죠.
=> 이를 1분마다 실행되는 worker를 통해 준실시간 형태로 시청기록을 확인할 수 있게 되었습니다.
(시청 후 최대 1분안에 생성되는 것이죠.)
- 사용자들의 모든 API 요청 기록은 google storage에 저장되고 있습니다.
=> 즉 xxxx_log 데이터를 유지하지 않아도 됩니다.
결론
위에 구현된 내용은 최대한 다른 장비를 붙이지 않고 현재 가동중인 시스템 안에서 구현한 내용입니다.
RDB 아닌 DDB 사용하거나 엘라스탁서치 등을 사용하면 더 간단하게 구현도 가능합니다.
듀랑고 라는 모바일 게임에서 로그를 수집하는 시스템 아키텍쳐에 대해 설명된 좋은글도 함께 첨부합니다. 링크