- Infra

최근 몇 년 동안 코로나로 인해 오프라인을 통한 개발자 컨퍼런스는 거의 없다시피 하다가 최근 들어 코로나가 비교적 잠잠해지고, 야외 마스크 해제가 허용되면서 몇몇 컨퍼런스는 오프라인으로 진행되기도 한다.
이번 NHN에서 진행한 NHN FORWARD 22는 들어보고 싶은 세션이 몇몇 있었던 차에 회사에서도 교육에 대해 적극적으로 지원해 주면서 평일이지만 다녀올 수 있었다.
시작하기에 앞서..
길었던 입장 대기줄과 다양한 컨텐츠
 (본 사진은 입장 대기열과는 무관합니다)
(본 사진은 입장 대기열과는 무관합니다)
처음 5층에 도착했을 때 이미 도착줄은 엄청 길었다. 입장에만 10분 정도는 기다린 것 같다. 사람이 많았던 만큼 교육 외에 즐길거리도 여럿 있었다.

4가지의 미니게임을 참여할 수 있었다.
틀린코드 찾기라니.. 어떻게 이런 생각을 했을까..

내가 들었던 세션은 다음과 같다.
- 11:00 ~ 11:40 : 트랙 2 - 편안한 휴식 시간을 지켜줄 안정적인 백엔드 운영과 개발 기법
- 13:00 ~ 13:40 : 트랙 2 - 분산 시스템에서 데이터를 전달하는 효율적인 방법
- 14:00 ~ 14:40 : 트랙 4 - Hadoop 개발 환경 구축과 MySQL 기반 배치를 Hadoop으로 옮긴 이야기
- 15:00 ~ 15:40 : 트랙 6 - 샵바이 주문 검색 성능 개선기
- 16:00 ~ 16:40 : 트랙 6 - 빠른 정보 제공을 위한 통계 시스템 개선기
- 17:00 ~ 17:40 : 트랙 3 - Face Style Transfer: 만화로 그린 내 얼굴은?
들었던 내용 중에는 이렇게도 해결하는구나 와 같이 가볍고 재미있게 들을 세션도 충분했고, AI 분야 쪽에서는 내가 모르는 게 너무 많다 보니 나에게는 너무 어렵게 다가오는 내용들도 많았다.
듣고 싶었지만 시간이 겹쳐서 혹은 사람이 너무 많아 듣지 못한 세션들은 NHN에서 추후에 동영상으로도 업로드해 준다고 하니 그때 들어봐야겠다.
오늘 정리해 볼 내용은 하루 동안 들었던 내용들을 정리해 보고자 한다. 여러 세션의 내용을 합쳐서 정리하다 보니 세션의 시간 순서와는 다를 수 있다는 점을 참고하길 바란다.
RDB를 사용한 시스템간의 Transaction 처리
서버 간의 트랜잭션 처리에 SAGA 패턴을 많이 사용한다. 하지만 SAGA 패턴을 시스템에 구현하는 게 말처럼 쉬운 일은 아니다. 그러던 중 발표 내용 중 재밌어 보이는 방법이 있어서 소개하고자 한다.
간단하게 하나의 과정을 살펴보자.
트랜잭션 처리 중 오류 발생
어떠한 서버에서 트랜잭션 처리가 필요하고, 트랜잭션 내에서 작업은 그림과 같이 위에서 아래의 순서로 진행된다고 하자.
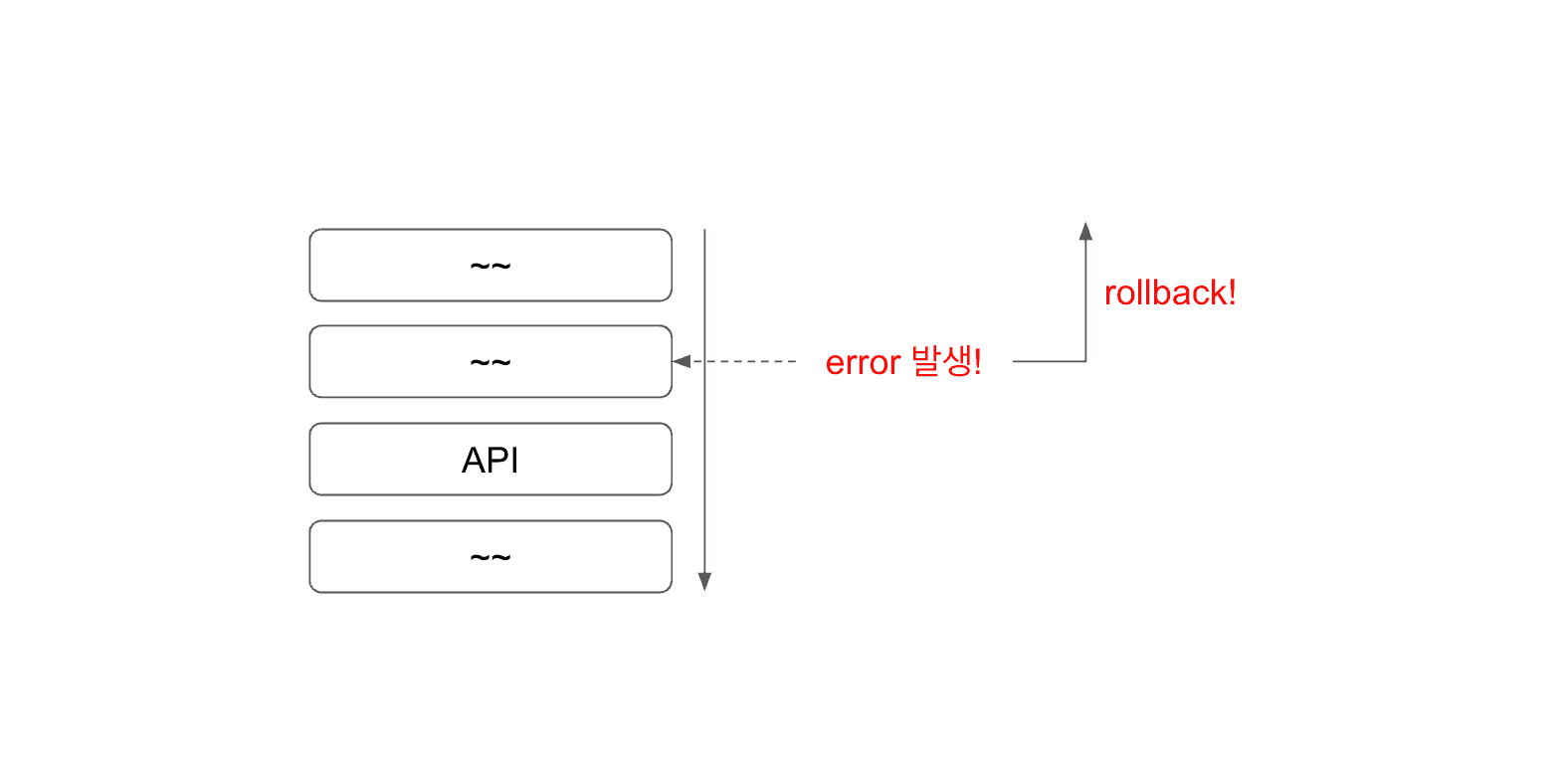
작업 중 오류가 발생하면 해당 transaction 을 rollback 처리할 수 있다.
API 호출 중 오류 발생
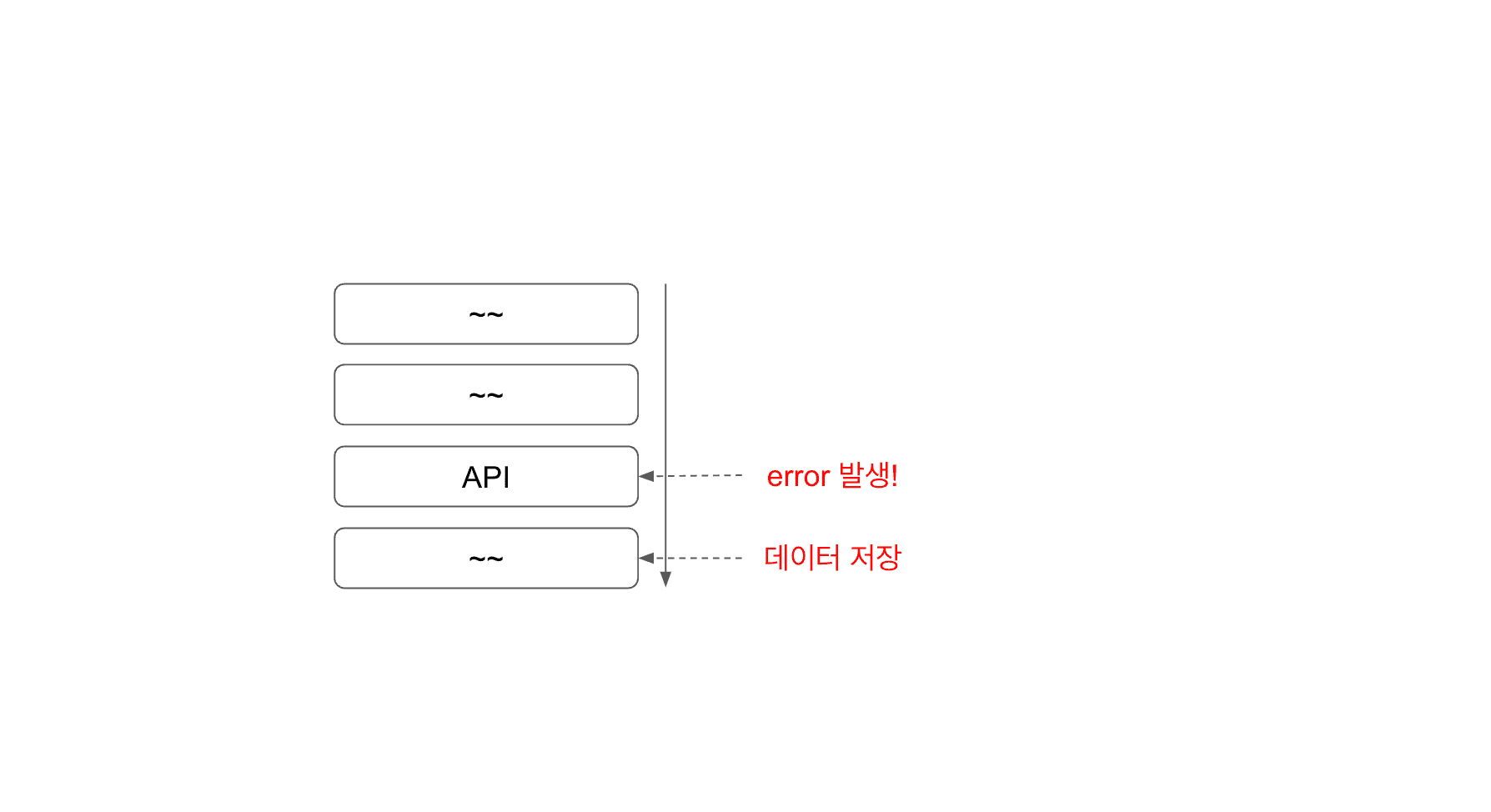 만약 내 로직에는 문제가 없었고, API호출했을 때 해당 서버에서 오류가 반환되었다고 가정해보자.
만약 내 로직에는 문제가 없었고, API호출했을 때 해당 서버에서 오류가 반환되었다고 가정해보자.
다른 서버를 호출한 API에서는 오류가 발생했지만, 내 서버에는 트랜잭션이 정상적으로 종료되었다. 여기서 다른 서버와 데이터의 정합성에 문제가 발생하게 된다.
(트랜잭션 내에서 외부 서버의 응답을 기다렸다 내 데이터를 commit / rollback을 결정하는 것은 API 호출에 대한 응답이 얼마나 걸릴지 모르기 때문에 권장하지 않는다.)
이를 어떻게 해결할 수 있을까?
API Retry

그림과 같이 api를 retry 해서 처리할 수 있을것이다.
하지만 이게 최선은 아니다. 왜냐하면 retry 역시 실패할 수 있다.
API 호출은 성공! 내 서버에서 오류가 난다면
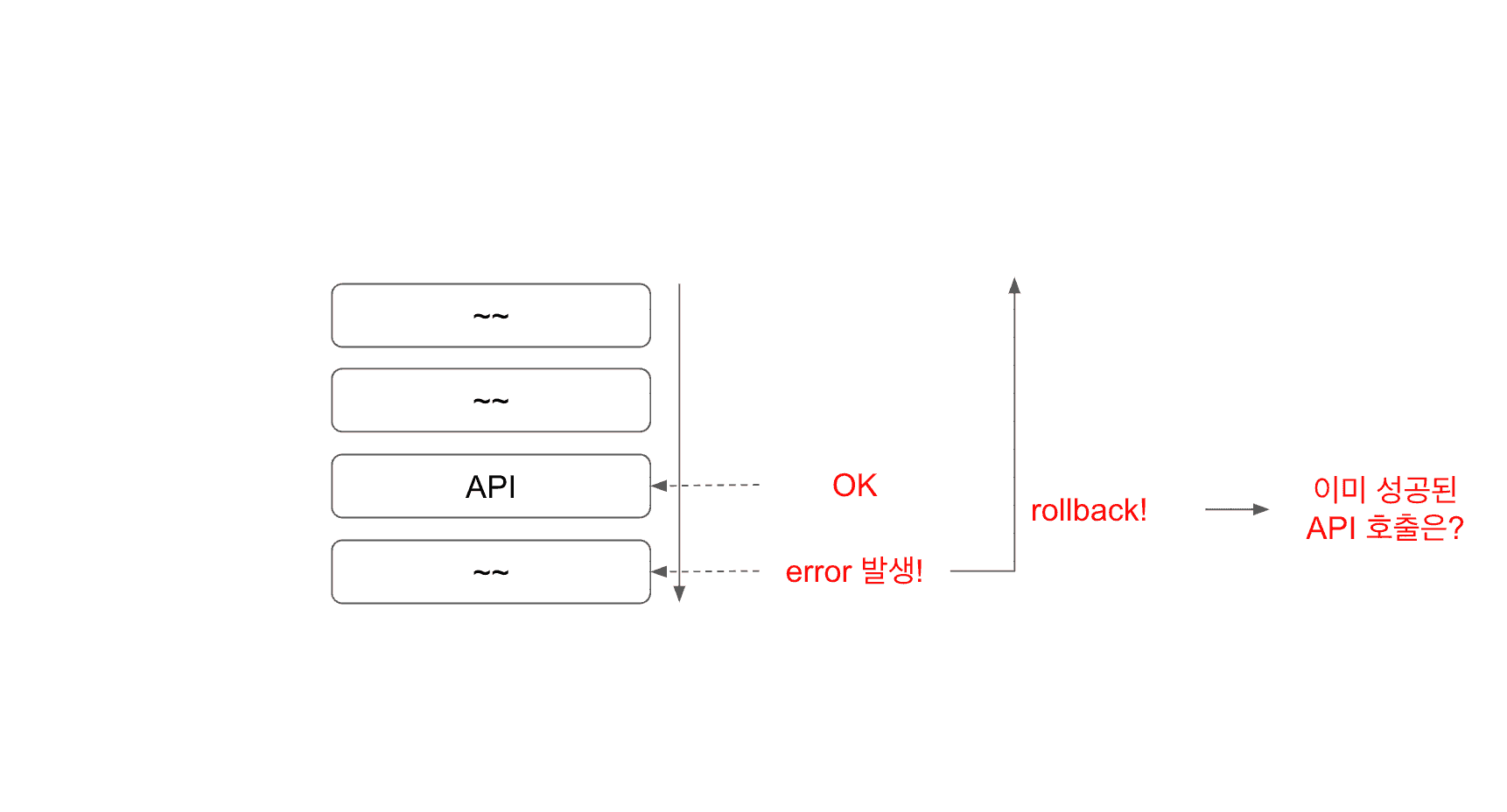
이번엔 api 통신은 성공했고, 그 이후 내 서버에서 오류가 발생한 상황을 가정해 보자.
내가 요청한 데이터를 API를 요청받은 서버에는 잘 저장되었을 것이다. 그런데 내 서버에서 오류가 발생하면서 내 서버에서는 rollback 하게 될 것이다.
이 또한 다른 서버와 내 서버가 데이터가 맞지 않는 상황이 발생한다.
해결
특정 세션에서 이 해결방법으로 RDB를 이용해 이를 해결하는 방법을 제안했다.
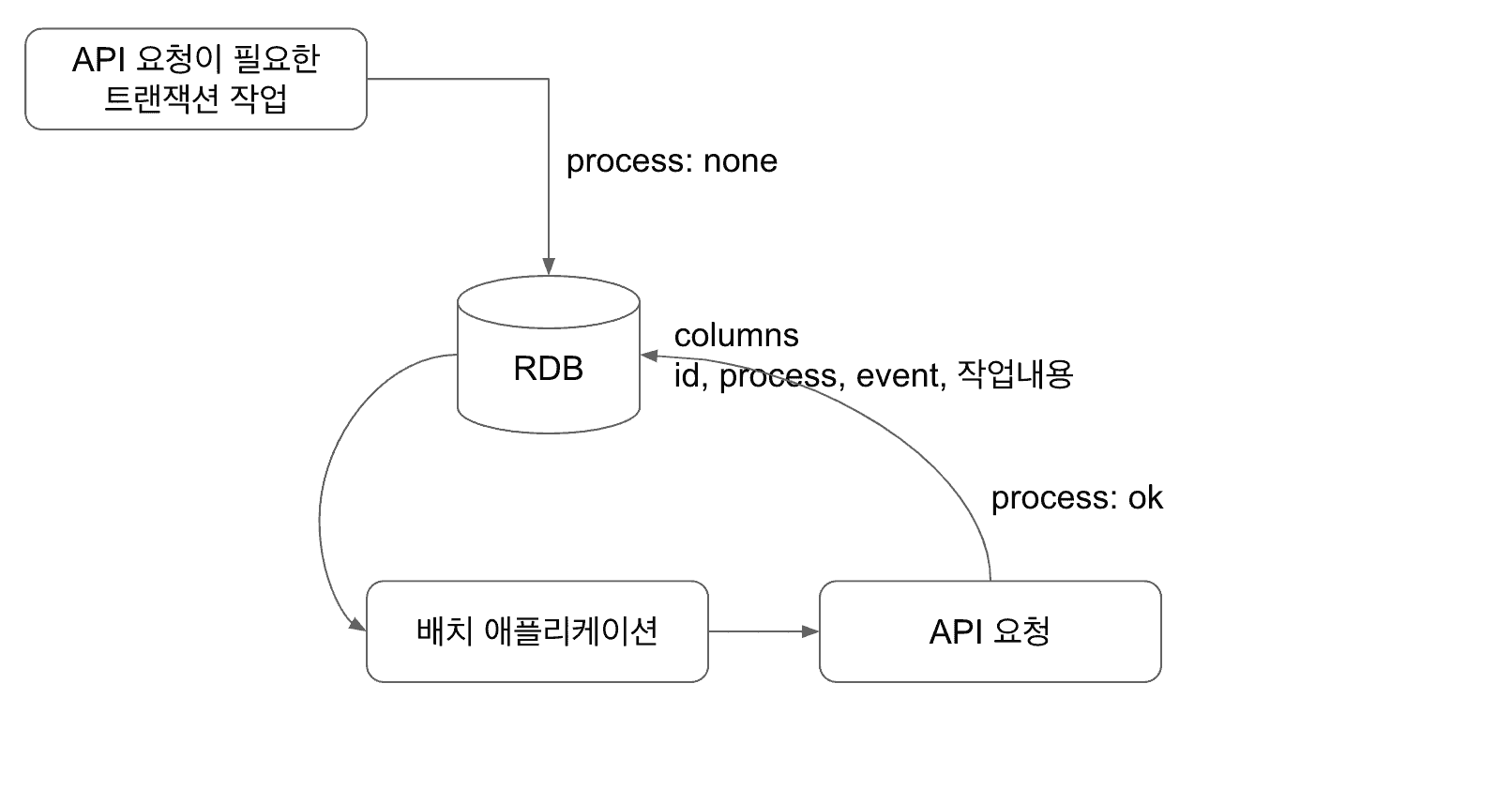
API 요청이 필요한 트랜잭션의 경우 RDB의 한 테이블에 row를 생성한다. 여기에는 이벤트 내용과 어떤 서버를 호출해야 할지 등의 정보가 들어갈 것이다. 그리고 배치 애플리케이션에서 process가 none인 데이터를 읽어와서 api를 요청하게 된다.
그리고 api요청이 성공으로 리턴되면 해당 process를 ok 로 바꿔서 작업이 완료됐다는것을 알려준다.
만약 실패하게되면 process를 여전히 none으로 두고 다음 배치 작업에서 이를 처리한다.
api 요청 후 row를 update하는 일만 하기때문에 여기서 실패가 생길 가능성은 극히 드물다.
정리
서버간 트랜잭션을 처리하는 방법은 여러가지가 있겠지만, RDB의 테이블을 이용해서 이렇게 처리한다는것이 특이하기는 했다.
당장 나에게 이렇게 설계해서 구현하시겠습니까? 라고 묻는다면 음 글쎄다.
물론 나쁜 방법이라고 생각하지는 않지만 설계 복잡도에 비해 얼마나 API 통신과 트랜잭션 사이의 문제가 잘 해결되었나라고 생각해 보면 그렇지 않다고 생각된다.
이런 방법도 있다. 정도로 이해하고 넘어가면 좋을 것 같다. (실제로 발표 내용에서도 이게 정답이다! 라기보다는 이런 방법도 있다~ 정도로 소개되었다.)
백엔드에서의 Cache 처리
Cache를 처리하는곳은 여러곳이 있다. 가장 첫번째로는 브라우저에서 해당 역할을 해준다. 개발자 도구를 열어 Network를 보면 304로 처리되는 경우가 있다. 이는 서버로부터 캐시에 대한 결과값을 받아 브라우저에서 해당 데이터를 Cache하는 경우이다.
API요청에 대해 백엔드는 해당 데이터를 어디에선가 가져와서 리턴해줄것이다. 백엔드가 같은 데이터를 여러곳에서 호출받는다면 그 때마다 디비 혹은 파일서버를 뒤져야할까? 이 때 리턴하는 리소스의 변화가 없다면 ETag라는 것을 사용할 수 있다.
브라우저에서 API를 요청할 때 일반적으로 60초동안 캐시하게 된다. (설정을 통해 변경 가능하다) 60초가 지나면 해당 api를 다시 서버로 요청하게 되는데, 이 때 ETag를 사용할 수 있다.
header에 ETag관련 값을 넣어주고, 백엔드가 이를 ETag를 통해 리턴하면 (body 없이) 브라우저는 이전에 Cache되어있던 데이터를 그대로 사용하게 된다.
클라이언트-서버간에 통신은 일어나겠지만 response되는 body가 없기때문에 트래픽을 아낄 수 있다.
참고로, nodejs express에서는 etag가 기본적으로 심어져있다. Express 공식 문서
주의할 점은, 리소스가 워낙 자주 변경되는 API라면 서버에서 ETag를 분석하는 로직이 항상 실행되게 되는데 오히려 api 통신이 느려지는 부작용이 있을 수 있다. (거의 매번 새로운 리소스가 리턴되는데, 캐시가 필요한지를 항상 검사하기 때문)
주기적으로 RDB를 읽어서 ES에 인덱싱하는 경우 데이터의 구멍이 발생할 수 있다.
RDB의 데이터를 ES로 인덱싱 하는 과정에서 RDB의 데이터가 누락될 수 있다. 어떨 때 그런 상황이 생길 수 있는지 살펴보자.
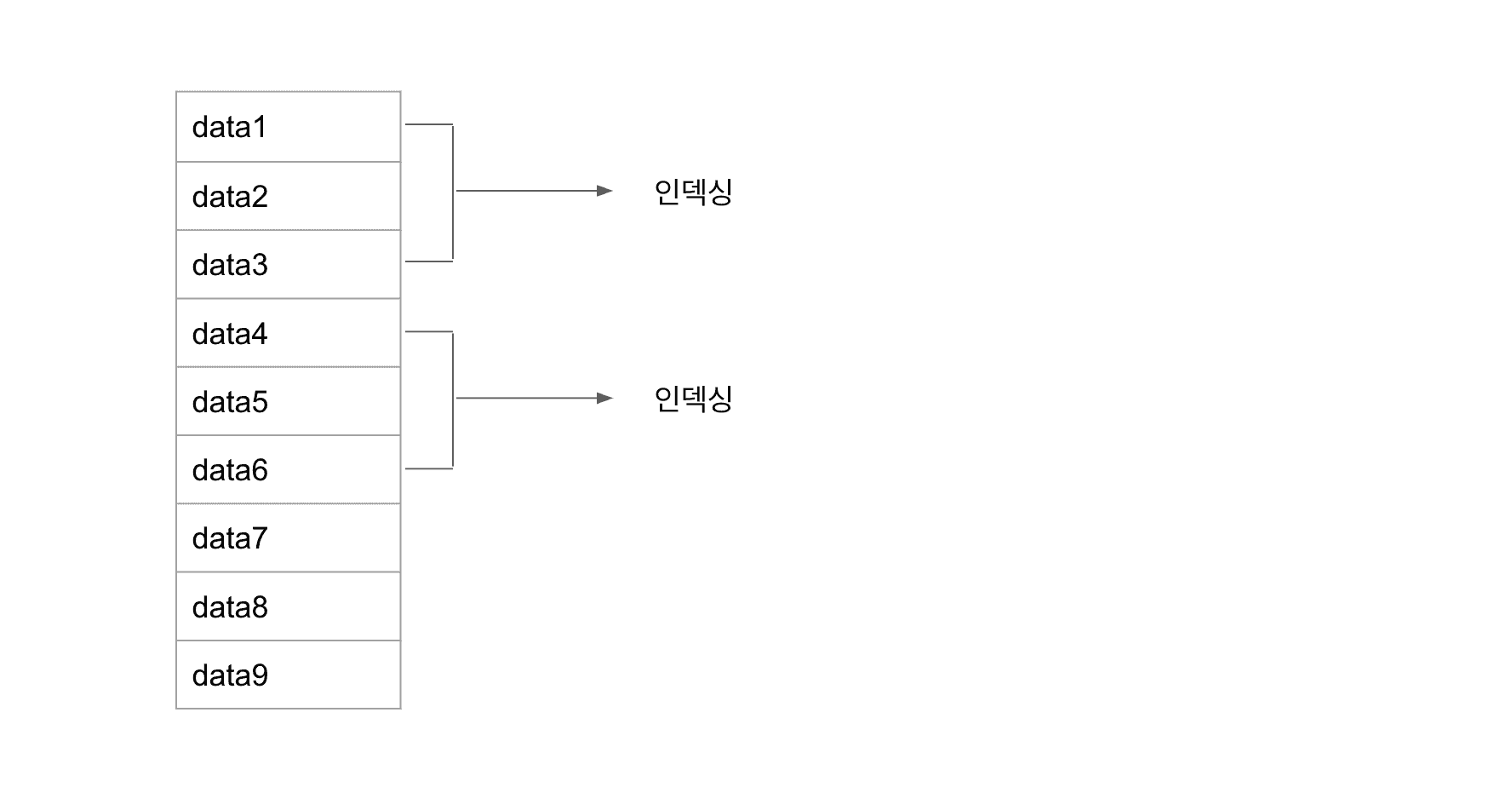
배치가 실행될 때 3개의 데이터가 생성되고, 3개씩 가져가서 인덱싱 한다고 생각해보자.
첫 번째 배치에서는 제일 위 3개가, 두 번째 배치에서는 그 다음 3개가 인덱싱 될 것이다.
그런데 만약, data3이 트랜잭션에서 실행중이고 아직 commit이 되지 않았다고 가정해보자.
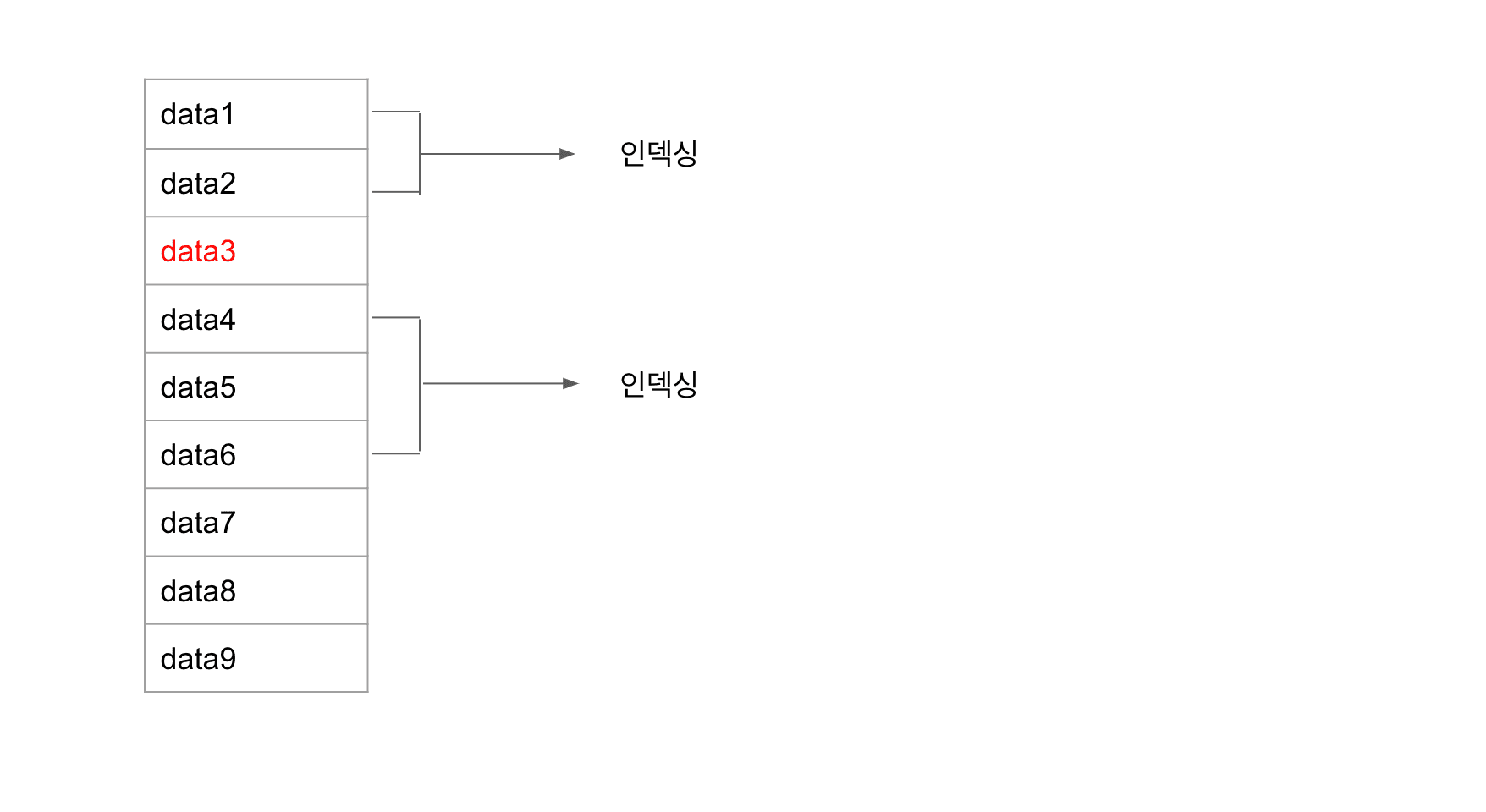
data3은 트랜잭션에 포함되어 아직 commit이 되지 않았다. 그래서 배치가 실행되어 인덱싱을 위한 데이터를 조회할 땐 data3이 조회되지 않는다. 그러면서 데이터의 누락이 발생했다.
트랜잭션은 commit이 되었지만, 다음 배치에서 인덱싱이 실행될 때에는 data3는 대상에서 빠지게 된다.
왜냐하면 data3의 데이터 생성시점을 보면 첫 번째 배치에서 인덱싱 되었어야 하지만, commit이 되지않아 대상에서 빠졌고,
두 번째 인덱생 배치에서는 data3의 생성시점이 배치의 인덱싱 타겟에는 맞지 않기 때문이다.
해결
- 데이터를 중첩해서 조회한 후 인덱싱한다.
예를들어, 8분마다 실행되는 배치에서 최근 10분간의 데이터를 조회한다. - 인덱싱을 위해 실행되는 배치에서 RDB의 Transaction Isolation Level을
Read uncommitted으로 설정하여 조회한다.
그러면 commit 되지 않은 데이터도 함께 조회할 수 있다.
(관련 POST)
정리
해당 세션의 주제는 인덱싱에 빠지는 데이터를 어떻게 처리할것인가는 아니었다. 하지만 이 내용을 본 블로그에 소개하는 이유는 트랜잭션의 commit 으로 인해 아직 데이터가 db에 반영되지 않았고, 다른 애플리케이션에서 해당 데이터를 조회할 때 데이터가 누락될 수 있다는 점을 한번 더 확인하기위해 작성해보았다.
이 세션에서 가장 중심이 되는 내용은 MySQL에서 조회하던것을 ES로 데이터를 옮겼고, 약 30일치의 상품 데이터를 조회했을 때 평균 19921ms 에서 381ms 로 속도가 증가했다는것이었다. (약 52배 빨라진 속도!)
Elastic Search의 성능은 최고다 (역시 돈인가)
통계 시스템 개선
마지막으로 통계시스템 개선에 대한 내용이다.
이 세션에서 소개된 로그 수집에 대한 아키텍쳐는 아마 많은 회사에서 비슷한 구조를 가지고 있을 것이다.
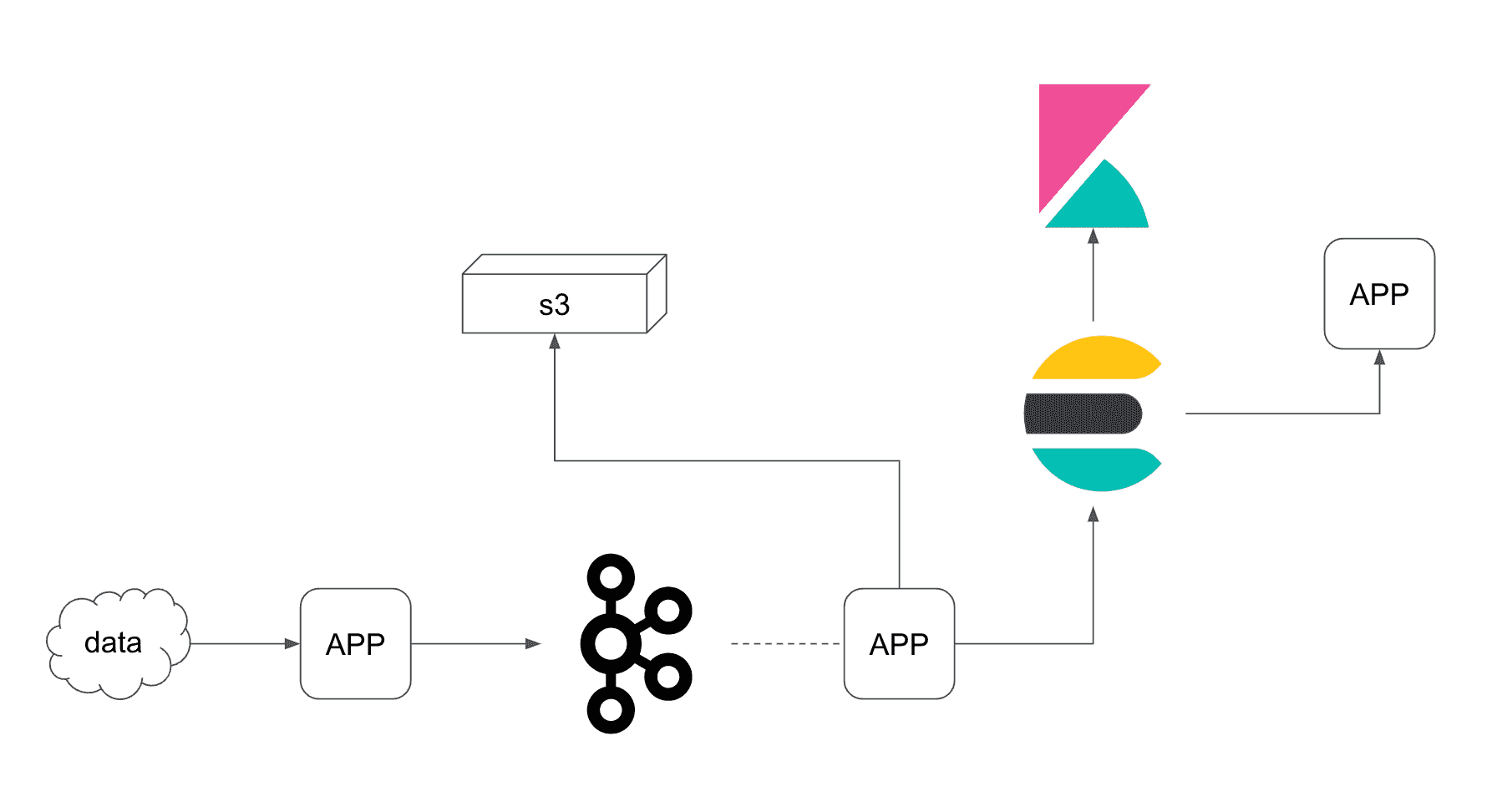
내가 현재 재직중인 회사에서도 이와 매우 비슷한 구조의 아키텍쳐를 채택하고있다.
(정확하게는 로그 수집을 위해서 동작하고있지는 않다.)
재밌는 것은 ES에 들어있는 데이터를 단순히 통계용이 아니더라도 충분히 사용할 곳이 많다.
저 데이터에서
- 구매정보만을 뽑는다면 => 얼마나 구매가 활발한지
- 페이지 전환에 대한 데이터를 뽑는다면 => 사용자의 페이지 전환에 대한 정보
- 사용자 정보만을 모으면 => 얼마나 많은 접속자가 있는지를 별도로 통계낼 수 있다.
즉, 한 개의 데이터를 통해 원하는 형태의 통계 데이터를 뽑을 수 있는 것이다.

정리
지난 회사에서 통계 시스템을 구현한적이 있었는데, 그 때에는 kafka 를 사용하지 않았다.
또 인메모리 에 저장되는 데이터를 배치를 통해 해결했었는데, 만약 kafka를 사용했더라면 좀 더 쉽게 구현하지 않았을 까 생각도 든다. 참고 게시글